Published at: 2025-10-30
DB Connector 1.x Operation Manual
This page documents an older version and is for maintenance only. New customers must not use it. Please use the DB Connector v2.x! DB Connector 2.x User Guide
1. Deployment Overview
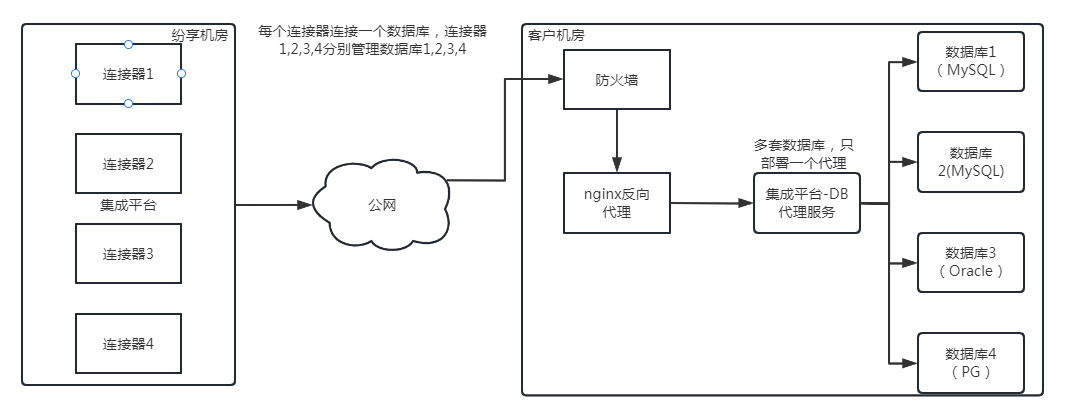 </img>
</img>Each connector links one customer database. Deploy a single Integration Platform proxy service inside the customer's data center to manage multiple databases.
The Integration Platform accesses the DB proxy service using the proxy account credentials configured by the administrator. The DB proxy service then connects to the actual database using the database account credentials.
Checklist:
- Is the customer data center allowed to access the public network?
- If the data center uses an IP whitelist, does it include ShareCRM's outbound IP addresses?
- Are the ports required by the proxy service open in the data center?
2. Configuration Screenshots
1. Primary Object
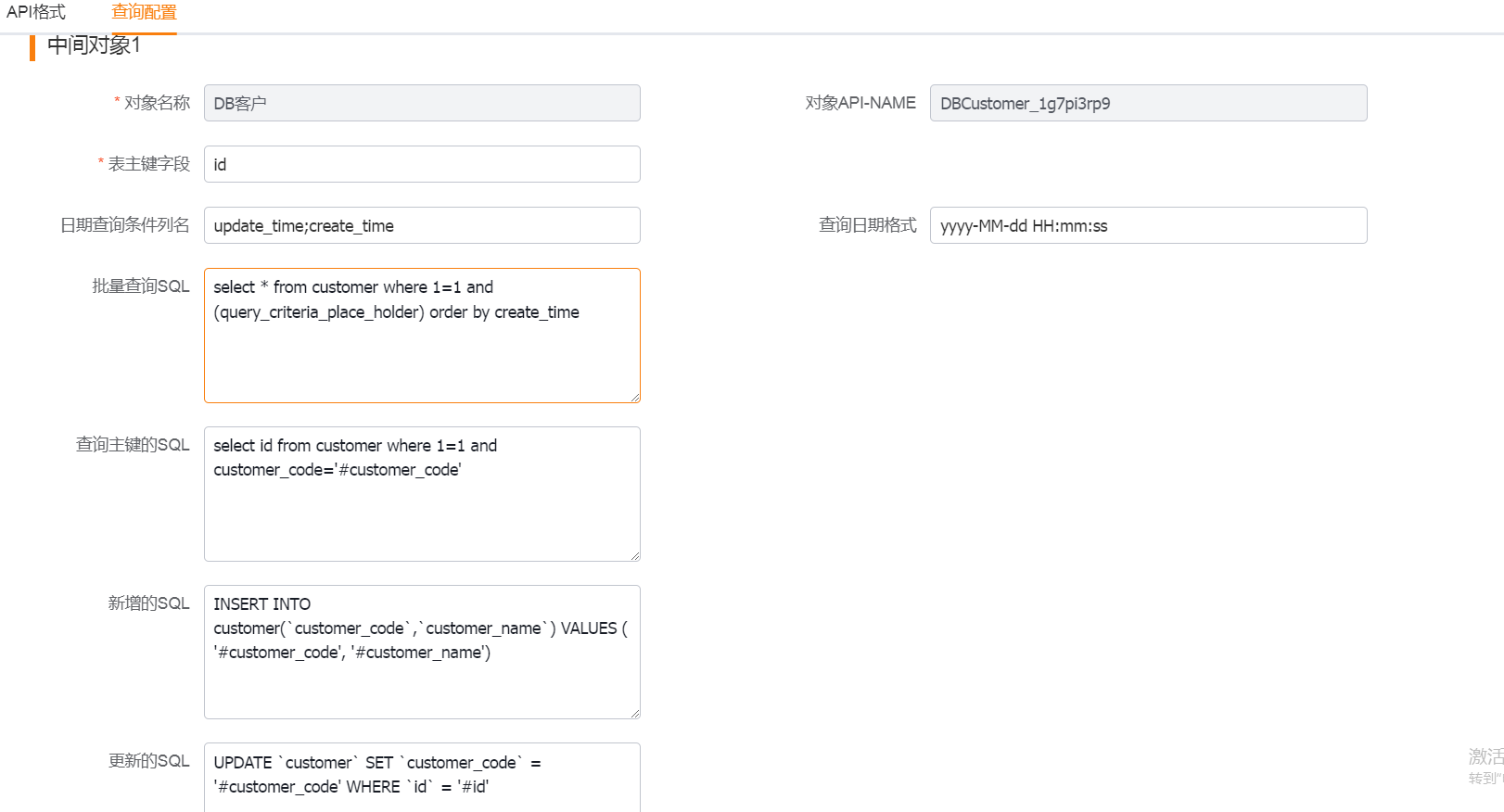 </img>
</img>2. Sub-object
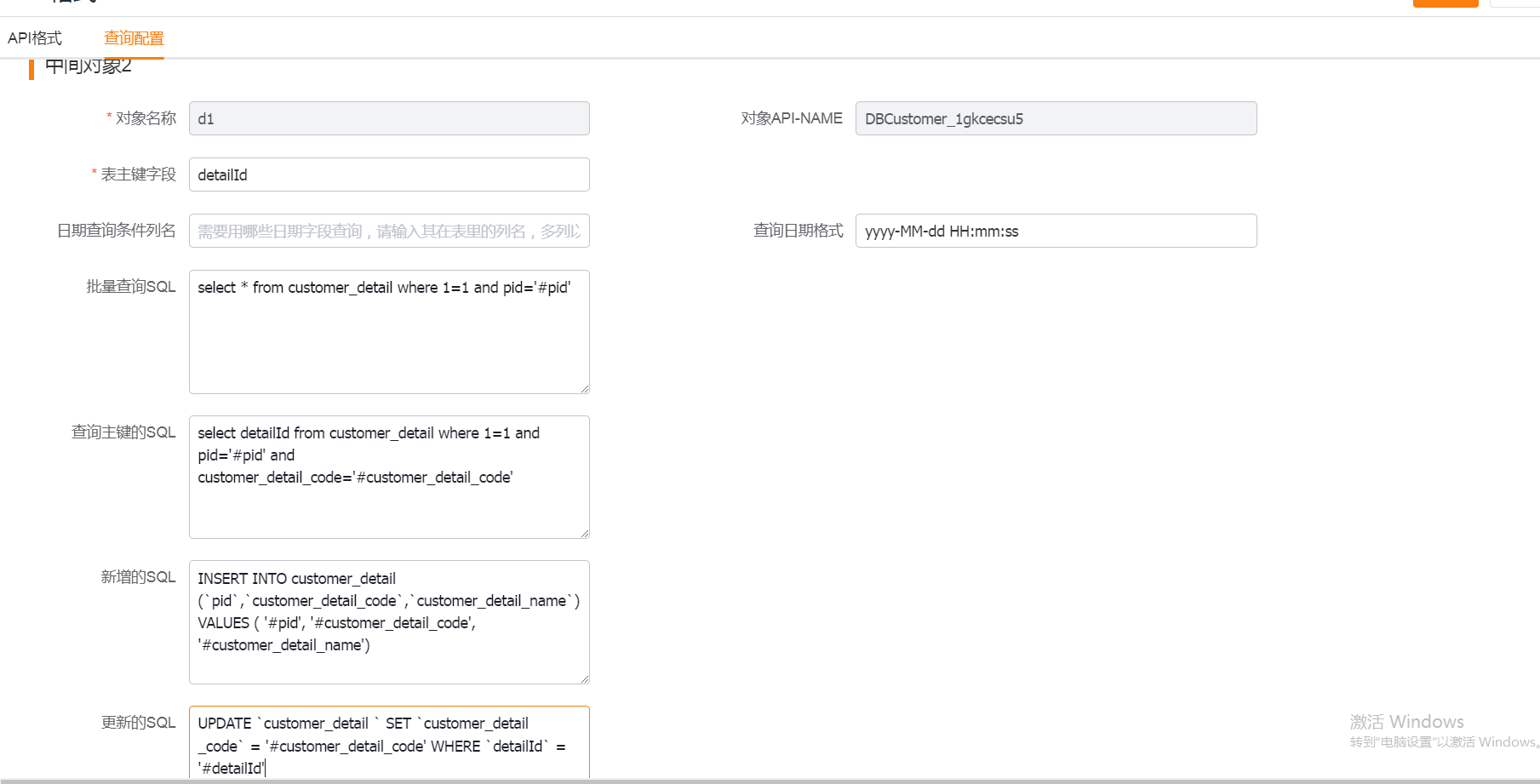 </img>
</img>3. Configuration Details
1. General Settings
1) Table primary key field: the unique identifier field for the table.
2) Date query columns: the time fields used for incremental polling. Use [;] or [,] to separate multiple fields. If the value contains [;], split by [;]; otherwise split by [,].
3) Query date format: format used to convert timestamps for queries.
4) Batch query SQL: SQL used for polling batch queries. If the Primary Object's SQL contains the placeholder [query_criteria_place_holder], the system will replace that placeholder with the generated criteria; otherwise the criteria will be appended to the SQL. Including an ORDER BY clause is recommended to reduce the chance of missing data.
5) SQL to query primary key: SQL to look up the primary key after an insert.
6) Insert SQL template: template used to insert records from CRM into the intermediate database. All replacement tokens should be written as '#fieldName'. If a sub-object needs to reference the primary object's primary key, use '#pid'.
7) Update SQL template: template used to update records from CRM into the intermediate database. Use the same '#fieldName' replacement convention. If a sub-object needs to reference the primary object's primary key, use '#pid'.
2. Special Configuration — Temporary Table
1) If you do not have Date query columns, ask the customer's IT team to create a temporary table in the target database by executing the SQL below (adjust the statements for specific database dialects if execution fails).
Purpose of the temporary table: without date fields, a direct read would always return the full table. The Integration Platform performs time-based polling against the temporary table. Each polling cycle reads data ordered by time from the temporary table while an asynchronous thread refreshes the temporary table by reading from the source table. During insertion the system compares data MD5 values — only rows with changed MD5 get their timestamp updated. The API can then fetch incremental data from the temporary table based on those updated timestamps.
First API call: temporary table is empty, the call returns no data and triggers an asynchronous refresh that populates the temporary table.
Second API call: the temporary table now contains data, which will be returned. When the poller reaches the last page, it triggers another asynchronous refresh, and the cycle continues.
-- PostgreSQL
CREATE TABLE sync_obj_record (
id int8 NOT NULL,
obj_name varchar NOT NULL,
md_str varchar NOT NULL,
data_id varchar NOT NULL,
data_body text NOT NULL,
"version" int NOT NULL,
create_time int8 NOT NULL,
update_time int8 NOT NULL,
CONSTRAINT sync_obj_record_pk PRIMARY KEY (id)
);
CREATE UNIQUE INDEX sync_obj_record_obj_name_idx ON sync_obj_record (obj_name,data_id);
-- ORACLE
CREATE TABLE sync_obj_record (
id NUMBER(19) NOT NULL,
obj_name VARCHAR2(255) NOT NULL,
md_str VARCHAR2(255) NOT NULL,
data_id VARCHAR2(255) NOT NULL,
data_body CLOB NOT NULL,
version NUMBER(19) NOT NULL,
create_time NUMBER(19) NOT NULL,
update_time NUMBER(19) NOT NULL,
CONSTRAINT sync_obj_record_pk PRIMARY KEY (id)
);CREATE UNIQUE INDEX sync_obj_record_obj_name_idx ON sync_obj_record (obj_name, data_id);</code>
-- SQLServerCREATE TABLE [dbo].[sync_obj_record] (
[id] bigint NOT NULL,
[obj_name] varchar(100) COLLATE Chinese_PRC_CI_AS NOT NULL,
[md_str] varchar(32) COLLATE Chinese_PRC_CI_AS NOT NULL,
[data_id] varchar(100) COLLATE Chinese_PRC_CI_AS NOT NULL,
[data_body] text COLLATE Chinese_PRC_CI_AS NOT NULL,
[version] int NOT NULL,
[create_time] bigint NOT NULL,
[update_time] bigint NOT NULL,
CONSTRAINT [PK__sync_obj__3213E83F46CC8028] PRIMARY KEY CLUSTERED ([id])
WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON)
ON [PRIMARY]
)
ON [PRIMARY]
TEXTIMAGE_ON [PRIMARY]
GOALTER TABLE [dbo].[sync_obj_record] SET (LOCK_ESCALATION = TABLE)
GO
CREATE UNIQUE NONCLUSTERED INDEX [sync_obj_record_u1]
ON [dbo].[sync_obj_record] (
[obj_name] ASC,
[data_id] ASC
)</code>
-- MySQL
CREATE TABLE sync_obj_record (
id INT NOT NULL,
obj_name VARCHAR(255) NOT NULL,
md_str VARCHAR(255) NOT NULL,
data_id VARCHAR(255) NOT NULL,
data_body TEXT NOT NULL,
version INT NOT NULL,
create_time BIGINT NOT NULL,
update_time BIGINT NOT NULL,
PRIMARY KEY (id)
);CREATE UNIQUE INDEX sync_obj_record_obj_name_idx ON sync_obj_record (obj_name, data_id);</code><h1 class="editor_js--header">4. How Configurations Work</h1><div class="editor_js--paragraph editor_js--paragraph__align-left">This section references configuration items 1–7 and the example SQL shown on the configuration pages.</div><h2 class="editor_js--header">1. Single-record Query</h2><div class="editor_js--qiniu_image"><div class="editor_js--qiniu_image__picture">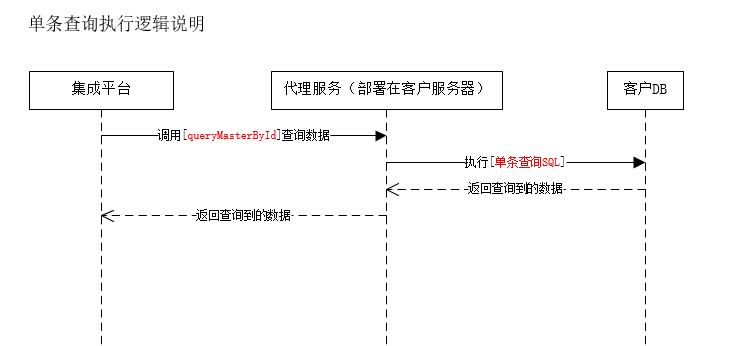 </img></div><div class="editor_js--qiniu_image__caption"></div></div><h3 class="editor_js--header">(1) Primary Object</h3><div class="editor_js--qiniu_image"><div class="editor_js--qiniu_image__picture">
</img></div><div class="editor_js--qiniu_image__caption"></div></div><h3 class="editor_js--header">(1) Primary Object</h3><div class="editor_js--qiniu_image"><div class="editor_js--qiniu_image__picture">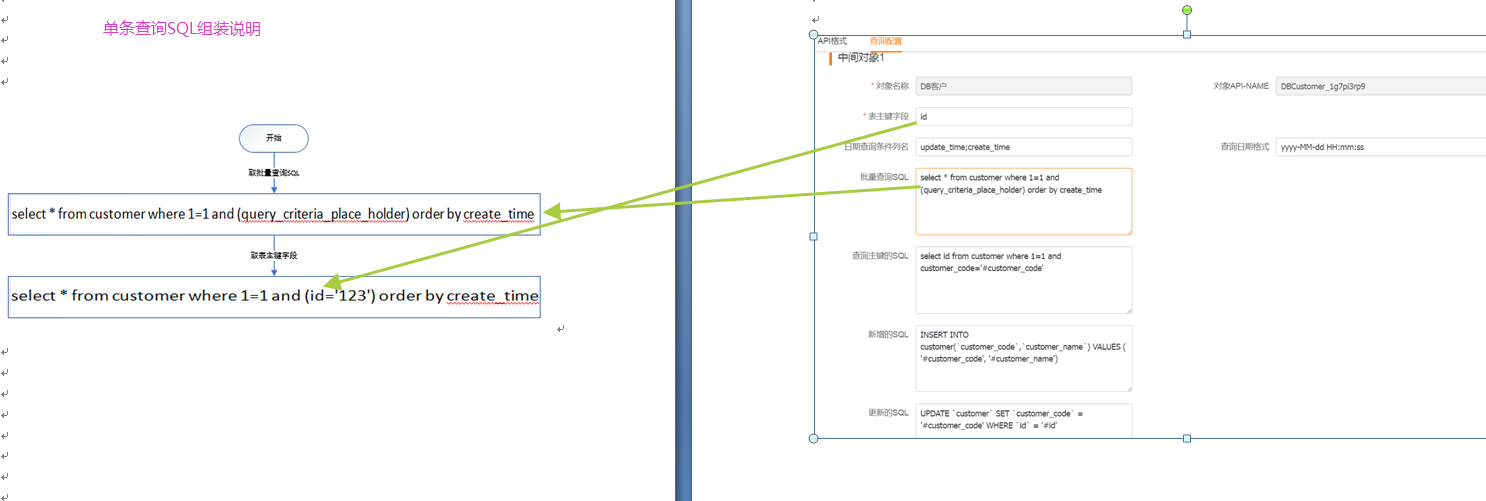 </img></div><div class="editor_js--qiniu_image__caption"></div></div><div class="editor_js--paragraph editor_js--paragraph__align-left">Query the primary record where the primary key value equals “123”.</div><div class="editor_js--paragraph editor_js--paragraph__align-left">Configurations used: 1 (table primary key field) and 4 (batch query SQL).</div><div class="editor_js--paragraph editor_js--paragraph__align-left">The system automatically generates the criteria: [primaryKeyField=’123’].</div><div class="editor_js--paragraph editor_js--paragraph__align-left">If the batch query SQL contains the placeholder, the system replaces it and produces a single-record query such as: [select * from customer where 1=1 and (id=’123’) order by create_time].</div><div class="editor_js--paragraph editor_js--paragraph__align-left">If there is no placeholder, the criteria are appended to the batch SQL (batch SQL + AND + criteria) to form the single-record query.</div><h3 class="editor_js--header">(2) Sub-object</h3><div class="editor_js--qiniu_image"><div class="editor_js--qiniu_image__picture">
</img></div><div class="editor_js--qiniu_image__caption"></div></div><div class="editor_js--paragraph editor_js--paragraph__align-left">Query the primary record where the primary key value equals “123”.</div><div class="editor_js--paragraph editor_js--paragraph__align-left">Configurations used: 1 (table primary key field) and 4 (batch query SQL).</div><div class="editor_js--paragraph editor_js--paragraph__align-left">The system automatically generates the criteria: [primaryKeyField=’123’].</div><div class="editor_js--paragraph editor_js--paragraph__align-left">If the batch query SQL contains the placeholder, the system replaces it and produces a single-record query such as: [select * from customer where 1=1 and (id=’123’) order by create_time].</div><div class="editor_js--paragraph editor_js--paragraph__align-left">If there is no placeholder, the criteria are appended to the batch SQL (batch SQL + AND + criteria) to form the single-record query.</div><h3 class="editor_js--header">(2) Sub-object</h3><div class="editor_js--qiniu_image"><div class="editor_js--qiniu_image__picture">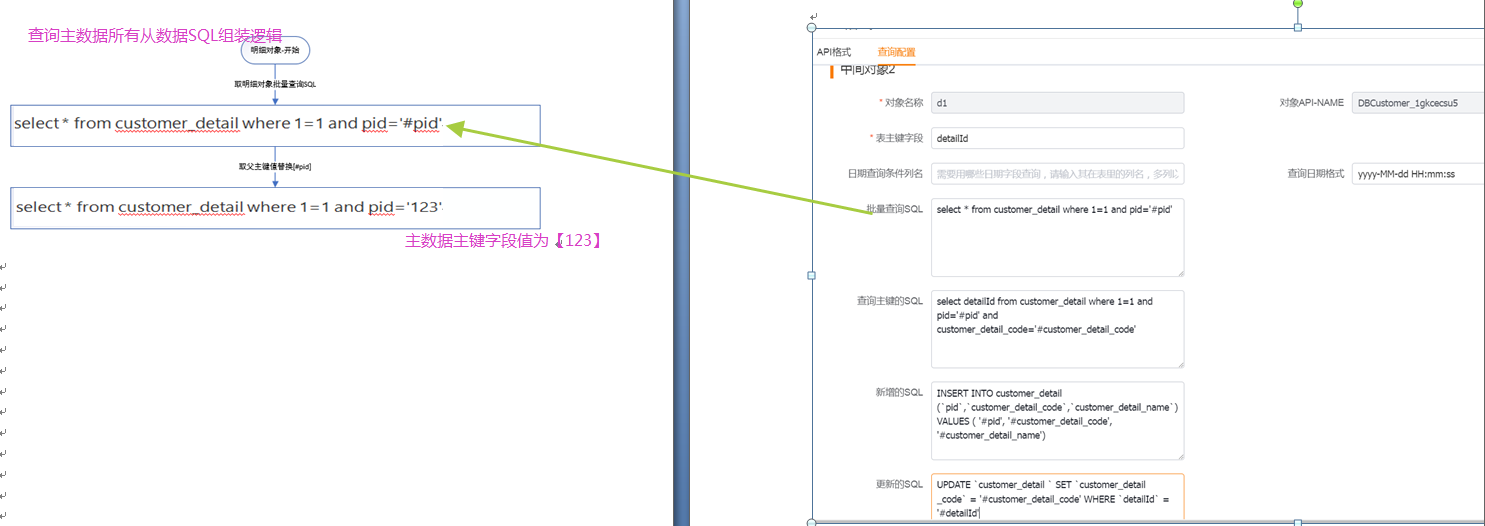 </img></div><div class="editor_js--qiniu_image__caption"></div></div><div class="editor_js--paragraph editor_js--paragraph__align-left">When Sub-objects exist, the system iterates the retrieved primary records and reads the primary key value (the primary record id, e.g., “123”).</div><div class="editor_js--paragraph editor_js--paragraph__align-left">It then replaces ‘#pid’ in the Sub-object’s batch query SQL with ‘123’, generating a query like: [select * from customer_detail where 1=1 and pid=’123’] to fetch the related detail rows.</div><h2 class="editor_js--header">2. Batch Query</h2><div class="editor_js--qiniu_image"><div class="editor_js--qiniu_image__picture">
</img></div><div class="editor_js--qiniu_image__caption"></div></div><div class="editor_js--paragraph editor_js--paragraph__align-left">When Sub-objects exist, the system iterates the retrieved primary records and reads the primary key value (the primary record id, e.g., “123”).</div><div class="editor_js--paragraph editor_js--paragraph__align-left">It then replaces ‘#pid’ in the Sub-object’s batch query SQL with ‘123’, generating a query like: [select * from customer_detail where 1=1 and pid=’123’] to fetch the related detail rows.</div><h2 class="editor_js--header">2. Batch Query</h2><div class="editor_js--qiniu_image"><div class="editor_js--qiniu_image__picture">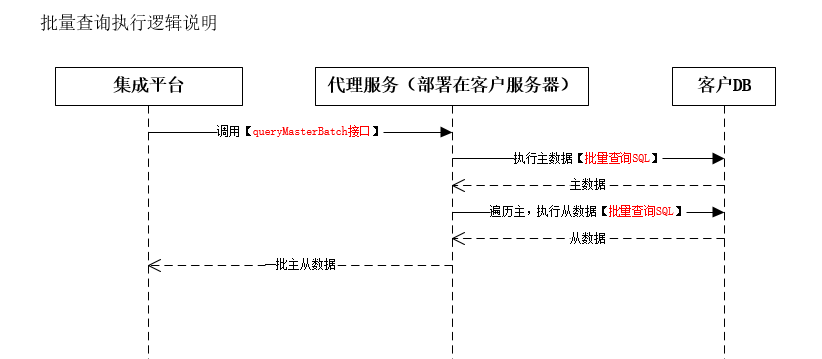 </img></div><div class="editor_js--qiniu_image__caption"></div></div><h3 class="editor_js--header">(1) Primary Object</h3><div class="editor_js--qiniu_image"><div class="editor_js--qiniu_image__picture">
</img></div><div class="editor_js--qiniu_image__caption"></div></div><h3 class="editor_js--header">(1) Primary Object</h3><div class="editor_js--qiniu_image"><div class="editor_js--qiniu_image__picture">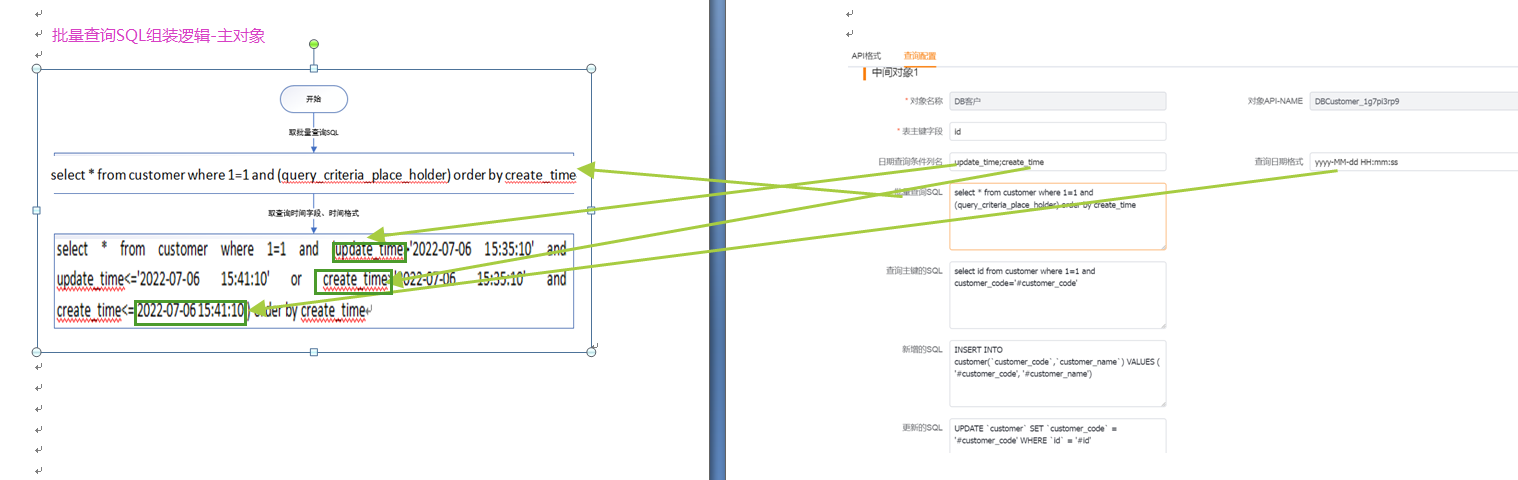 </img></div><div class="editor_js--qiniu_image__caption"></div></div><div class="editor_js--paragraph editor_js--paragraph__align-left">Start timestamp: 1657092910000, End timestamp: 1657093270000.</div><div class="editor_js--paragraph editor_js--paragraph__align-left">Configurations used: 2 (date query columns), 3 (query date format), and 4 (batch query SQL).</div><div class="editor_js--paragraph editor_js--paragraph__align-left">The system converts the timestamps using the date format from 3, resulting in: Start: 2022-07-06 15:35:10, End: 2022-07-06 15:41:10.</div><div class="editor_js--paragraph editor_js--paragraph__align-left">Using 2 (date query columns): If the setting contains [;], split by [;] into multiple time fields; otherwise split by [,]. The system composes the time criteria by combining each field with the start and end times, resulting in a condition like: [update_time>’2022-07-06 15:35:10’ and update_time<=’2022-07-06 15:41:10’ or create_time>’2022-07-06 15:35:10’ and create_time<=’2022-07-06 15:41:10’].</div><div class="editor_js--paragraph editor_js--paragraph__align-left">Apply the condition to the Primary Object’s batch SQL. If the batch SQL contains the placeholder, replace it; otherwise append the condition to the SQL (batch SQL + AND + condition). Example result: [select * from customer where 1=1 and (update_time>‘2022-07-06 15:35:10’ and update_time<=’2022-07-06 15:41:10’ or create_time>‘2022-07-06 15:35:10’ and create_time<=’2022-07-06 15:41:10’) order by create_time].</div><h3 class="editor_js--header">(2) Sub-object — see Single-record Query logic</h3><div class="editor_js--paragraph editor_js--paragraph__align-left">For Sub-objects, the system iterates the Primary Object results, extracts each primary key value (e.g., ‘123’), replaces ‘#pid’ in the Sub-object’s batch SQL with that ID, and runs queries like: [select * from customer_detail where 1=1 and pid=’123’].</div><h2 class="editor_js--header">3. Create Records</h2><div class="editor_js--qiniu_image"><div class="editor_js--qiniu_image__picture">
</img></div><div class="editor_js--qiniu_image__caption"></div></div><div class="editor_js--paragraph editor_js--paragraph__align-left">Start timestamp: 1657092910000, End timestamp: 1657093270000.</div><div class="editor_js--paragraph editor_js--paragraph__align-left">Configurations used: 2 (date query columns), 3 (query date format), and 4 (batch query SQL).</div><div class="editor_js--paragraph editor_js--paragraph__align-left">The system converts the timestamps using the date format from 3, resulting in: Start: 2022-07-06 15:35:10, End: 2022-07-06 15:41:10.</div><div class="editor_js--paragraph editor_js--paragraph__align-left">Using 2 (date query columns): If the setting contains [;], split by [;] into multiple time fields; otherwise split by [,]. The system composes the time criteria by combining each field with the start and end times, resulting in a condition like: [update_time>’2022-07-06 15:35:10’ and update_time<=’2022-07-06 15:41:10’ or create_time>’2022-07-06 15:35:10’ and create_time<=’2022-07-06 15:41:10’].</div><div class="editor_js--paragraph editor_js--paragraph__align-left">Apply the condition to the Primary Object’s batch SQL. If the batch SQL contains the placeholder, replace it; otherwise append the condition to the SQL (batch SQL + AND + condition). Example result: [select * from customer where 1=1 and (update_time>‘2022-07-06 15:35:10’ and update_time<=’2022-07-06 15:41:10’ or create_time>‘2022-07-06 15:35:10’ and create_time<=’2022-07-06 15:41:10’) order by create_time].</div><h3 class="editor_js--header">(2) Sub-object — see Single-record Query logic</h3><div class="editor_js--paragraph editor_js--paragraph__align-left">For Sub-objects, the system iterates the Primary Object results, extracts each primary key value (e.g., ‘123’), replaces ‘#pid’ in the Sub-object’s batch SQL with that ID, and runs queries like: [select * from customer_detail where 1=1 and pid=’123’].</div><h2 class="editor_js--header">3. Create Records</h2><div class="editor_js--qiniu_image"><div class="editor_js--qiniu_image__picture">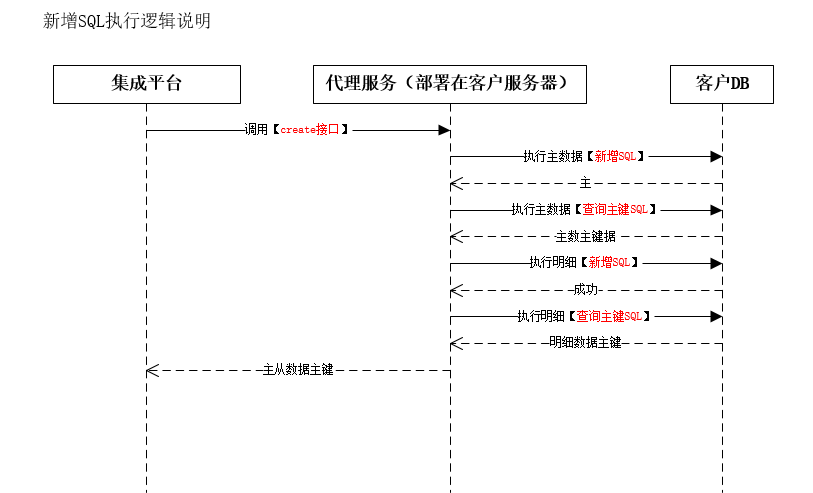 </img></div><div class="editor_js--qiniu_image__caption"></div></div><h3 class="editor_js--header">(1) Primary Object — Insert</h3><div class="editor_js--qiniu_image"><div class="editor_js--qiniu_image__picture">
</img></div><div class="editor_js--qiniu_image__caption"></div></div><h3 class="editor_js--header">(1) Primary Object — Insert</h3><div class="editor_js--qiniu_image"><div class="editor_js--qiniu_image__picture">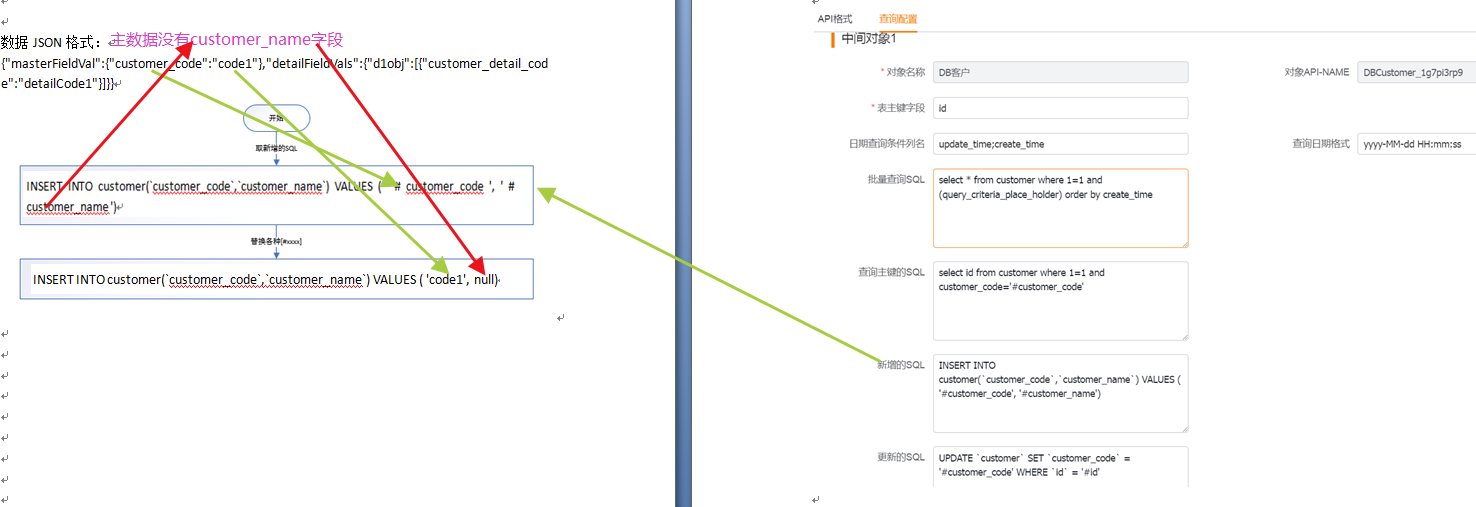 </img></div><div class="editor_js--qiniu_image__caption"></div></div><div class="editor_js--paragraph editor_js--paragraph__align-left">Example payload: {“masterFieldVal”:{“customer_code”:”code1”},”detailFieldVals”:{“d1obj”:[{“customer_detail_code”:”detailCode1”}]}}</div><div class="editor_js--paragraph editor_js--paragraph__align-left">Configurations used: Primary/Sub-object 5 (SQL to query primary key) and 6 (insert SQL template).</div><div class="editor_js--paragraph editor_js--paragraph__align-left">Apply 6 (insert SQL template) for the primary object: replace ‘#customer_code’ with the primary field value ‘code1’. If ‘#customer_name’ has a null value in the payload, replace it with null. Example resulting SQL: [INSERT INTO customer(
</img></div><div class="editor_js--qiniu_image__caption"></div></div><div class="editor_js--paragraph editor_js--paragraph__align-left">Example payload: {“masterFieldVal”:{“customer_code”:”code1”},”detailFieldVals”:{“d1obj”:[{“customer_detail_code”:”detailCode1”}]}}</div><div class="editor_js--paragraph editor_js--paragraph__align-left">Configurations used: Primary/Sub-object 5 (SQL to query primary key) and 6 (insert SQL template).</div><div class="editor_js--paragraph editor_js--paragraph__align-left">Apply 6 (insert SQL template) for the primary object: replace ‘#customer_code’ with the primary field value ‘code1’. If ‘#customer_name’ has a null value in the payload, replace it with null. Example resulting SQL: [INSERT INTO customer(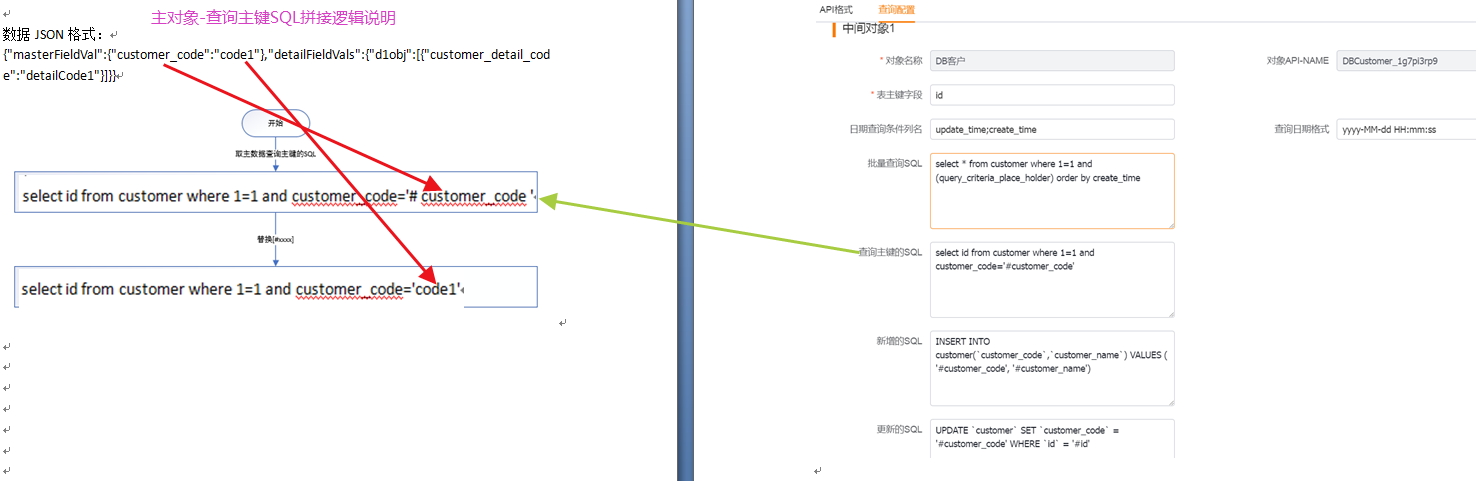 </img></div><div class="editor_js--qiniu_image__caption"></div></div><div class="editor_js--paragraph editor_js--paragraph__align-left">Apply 5 (SQL to query primary key): replace ‘#customer_code’ with ‘code1’ and run: [select id from customer where 1=1 and customer_code=’code1’] to retrieve the inserted primary key.</div><h3 class="editor_js--header">(3) Sub-object — Insert</h3><div class="editor_js--qiniu_image"><div class="editor_js--qiniu_image__picture">
</img></div><div class="editor_js--qiniu_image__caption"></div></div><div class="editor_js--paragraph editor_js--paragraph__align-left">Apply 5 (SQL to query primary key): replace ‘#customer_code’ with ‘code1’ and run: [select id from customer where 1=1 and customer_code=’code1’] to retrieve the inserted primary key.</div><h3 class="editor_js--header">(3) Sub-object — Insert</h3><div class="editor_js--qiniu_image"><div class="editor_js--qiniu_image__picture">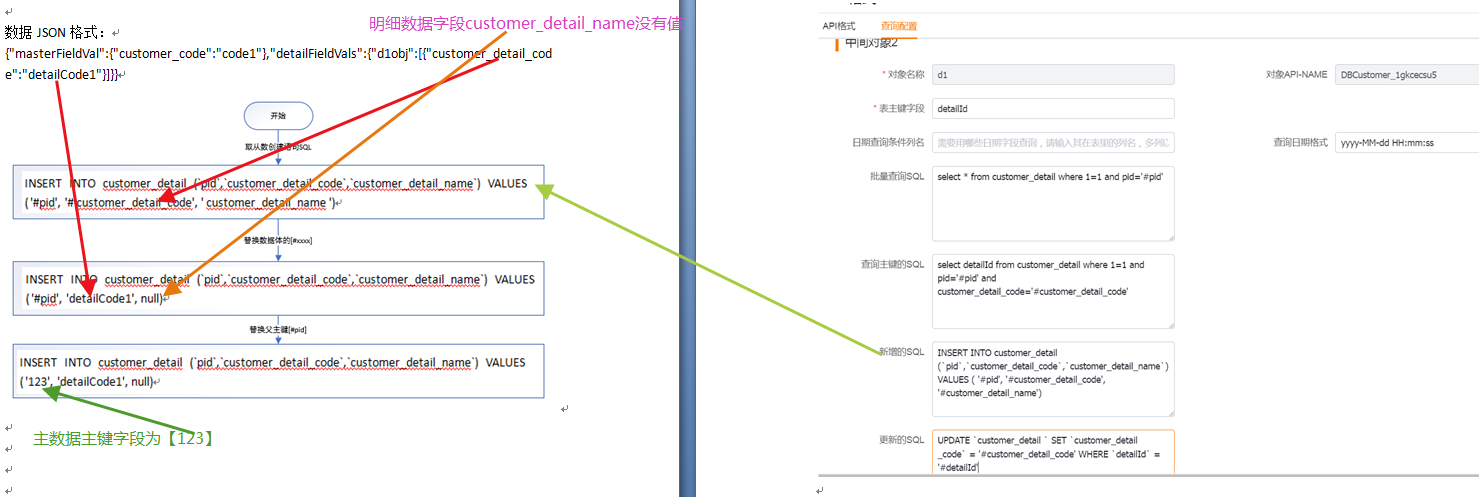 </img></div><div class="editor_js--qiniu_image__caption"></div></div><div class="editor_js--paragraph editor_js--paragraph__align-left">Apply 6 (insert SQL template) for the Sub-object: replace ‘#customer_detail_code’ with ‘detailCode1’. If ‘#customer_detail_name’ is null, replace it with null. The preliminary insert SQL becomes: [INSERT INTO customer_detail (
</img></div><div class="editor_js--qiniu_image__caption"></div></div><div class="editor_js--paragraph editor_js--paragraph__align-left">Apply 6 (insert SQL template) for the Sub-object: replace ‘#customer_detail_code’ with ‘detailCode1’. If ‘#customer_detail_name’ is null, replace it with null. The preliminary insert SQL becomes: [INSERT INTO customer_detail (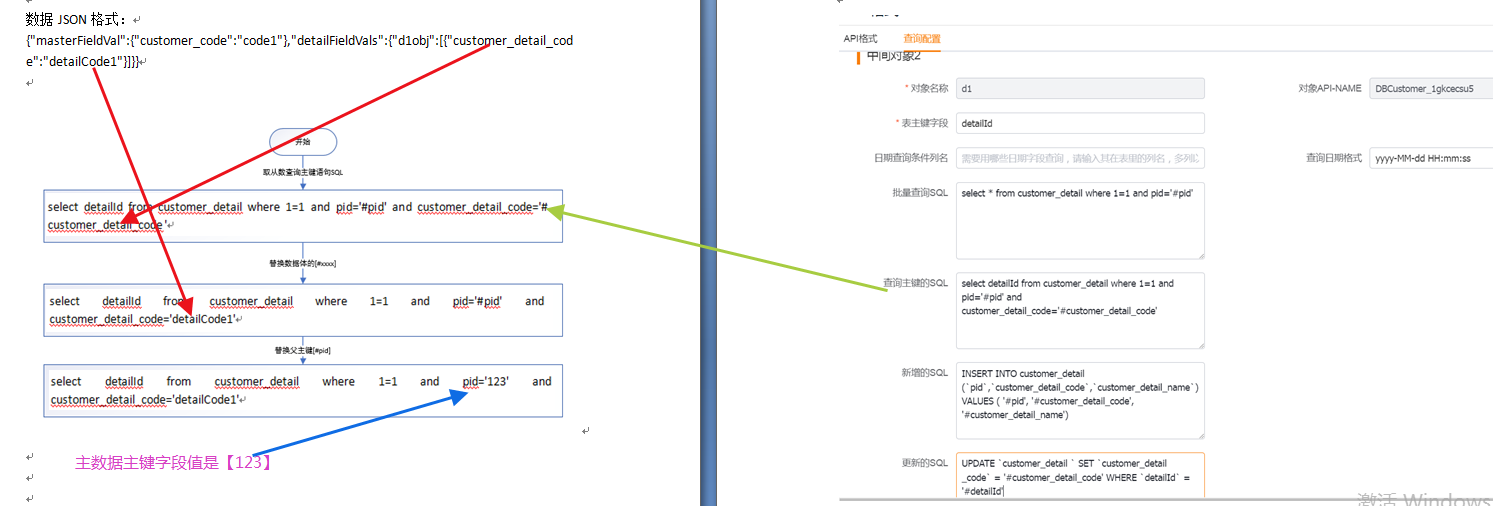 </img></div><div class="editor_js--qiniu_image__caption"></div></div><div class="editor_js--paragraph editor_js--paragraph__align-left">Apply 5 (SQL to query primary key) for the Sub-object: replace ‘#customer_detail_code’ with ‘detailCode1’ and ‘#pid’ remains as ‘#pid’ until the primary key is available. Preliminary SQL: [select detailId from customer_detail where 1=1 and pid=’#pid’ and customer_detail_code=’detailCode1’].</div><h3 class="editor_js--header">(5) Execution Order for Primary/Sub-object SQL (Non-transactional)</h3><div class="editor_js--paragraph editor_js--paragraph__align-left">1. Execute the primary object INSERT SQL.</div><div class="editor_js--paragraph editor_js--paragraph__align-left">2. On success, run the primary object’s SQL to query the newly inserted primary key (for example, ‘1234’).</div><div class="editor_js--paragraph editor_js--paragraph__align-left">3. Replace ‘#pid’ in the Sub-object’s INSERT and primary-key-query SQL with ‘1234’, producing final Sub-object SQL such as: [INSERT INTO customer_detail (
</img></div><div class="editor_js--qiniu_image__caption"></div></div><div class="editor_js--paragraph editor_js--paragraph__align-left">Apply 5 (SQL to query primary key) for the Sub-object: replace ‘#customer_detail_code’ with ‘detailCode1’ and ‘#pid’ remains as ‘#pid’ until the primary key is available. Preliminary SQL: [select detailId from customer_detail where 1=1 and pid=’#pid’ and customer_detail_code=’detailCode1’].</div><h3 class="editor_js--header">(5) Execution Order for Primary/Sub-object SQL (Non-transactional)</h3><div class="editor_js--paragraph editor_js--paragraph__align-left">1. Execute the primary object INSERT SQL.</div><div class="editor_js--paragraph editor_js--paragraph__align-left">2. On success, run the primary object’s SQL to query the newly inserted primary key (for example, ‘1234’).</div><div class="editor_js--paragraph editor_js--paragraph__align-left">3. Replace ‘#pid’ in the Sub-object’s INSERT and primary-key-query SQL with ‘1234’, producing final Sub-object SQL such as: [INSERT INTO customer_detail (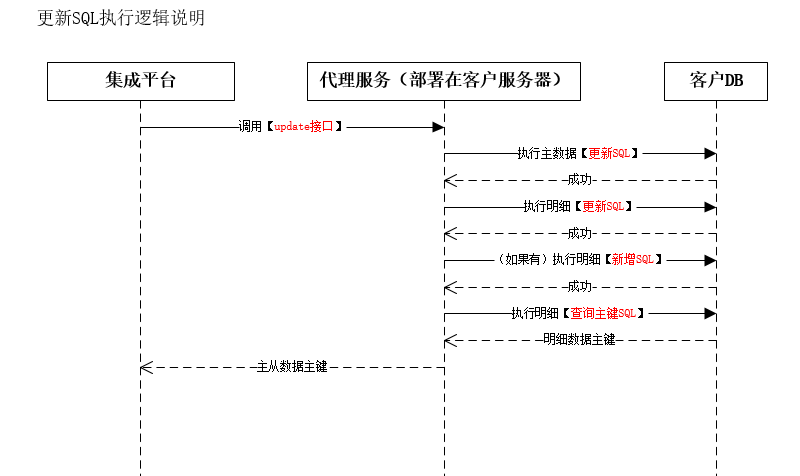 </img></div><div class="editor_js--qiniu_image__caption"></div></div><h3 class="editor_js--header">(1) Primary Object — Update</h3><div class="editor_js--qiniu_image"><div class="editor_js--qiniu_image__picture">
</img></div><div class="editor_js--qiniu_image__caption"></div></div><h3 class="editor_js--header">(1) Primary Object — Update</h3><div class="editor_js--qiniu_image"><div class="editor_js--qiniu_image__picture">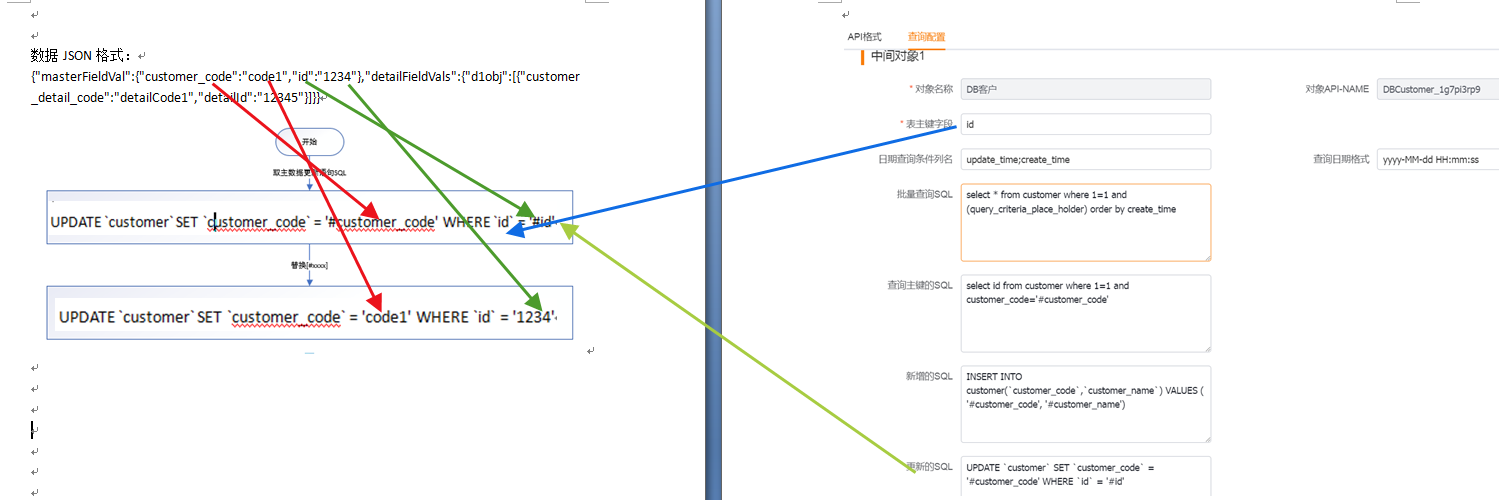 </img></div><div class="editor_js--qiniu_image__caption"></div></div><div class="editor_js--paragraph editor_js--paragraph__align-left">Example payload: {“masterFieldVal”:{“customer_code”:”code1”,”id”:”1234”},”detailFieldVals”:{“d1obj”:[{“customer_detail_code”:”detailCode1”,”detailId”:”12345”}]}}</div><div class="editor_js--paragraph editor_js--paragraph__align-left">Configurations used: Primary/Sub-object 7 (update SQL). If the Sub-object contains new detail rows, the Sub-object’s 5 (SQL to query primary key) and 6 (insert SQL template) are also used.</div><div class="editor_js--paragraph editor_js--paragraph__align-left">Apply 7 (update SQL) for the primary object: replace ‘#customer_code’ with ‘code1’ and ‘#id’ with ‘1234’. Resulting SQL: [UPDATE
</img></div><div class="editor_js--qiniu_image__caption"></div></div><div class="editor_js--paragraph editor_js--paragraph__align-left">Example payload: {“masterFieldVal”:{“customer_code”:”code1”,”id”:”1234”},”detailFieldVals”:{“d1obj”:[{“customer_detail_code”:”detailCode1”,”detailId”:”12345”}]}}</div><div class="editor_js--paragraph editor_js--paragraph__align-left">Configurations used: Primary/Sub-object 7 (update SQL). If the Sub-object contains new detail rows, the Sub-object’s 5 (SQL to query primary key) and 6 (insert SQL template) are also used.</div><div class="editor_js--paragraph editor_js--paragraph__align-left">Apply 7 (update SQL) for the primary object: replace ‘#customer_code’ with ‘code1’ and ‘#id’ with ‘1234’. Resulting SQL: [UPDATE 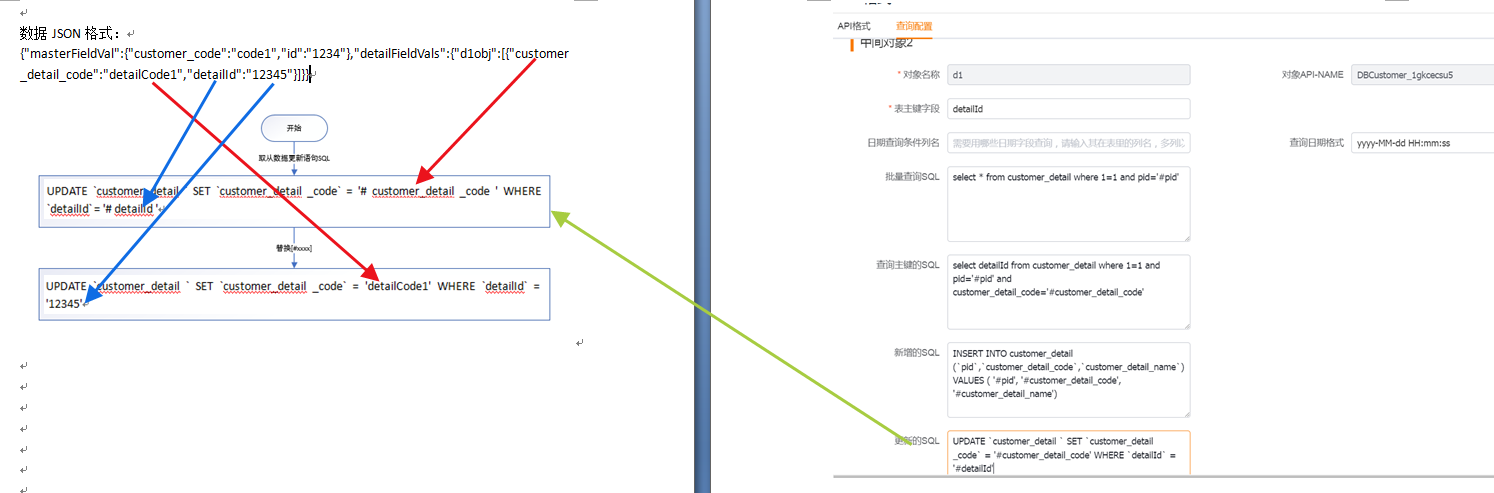 </img></div><div class="editor_js--qiniu_image__caption"></div></div><div class="editor_js--paragraph editor_js--paragraph__align-left">Apply 7 (update SQL) for the Sub-object: replace ‘#customer_detail_code’ with ‘detailCode1’ and ‘#detailId’ with ‘12345’. Example resulting SQL: [UPDATE
</img></div><div class="editor_js--qiniu_image__caption"></div></div><div class="editor_js--paragraph editor_js--paragraph__align-left">Apply 7 (update SQL) for the Sub-object: replace ‘#customer_detail_code’ with ‘detailCode1’ and ‘#detailId’ with ‘12345’. Example resulting SQL: [UPDATE 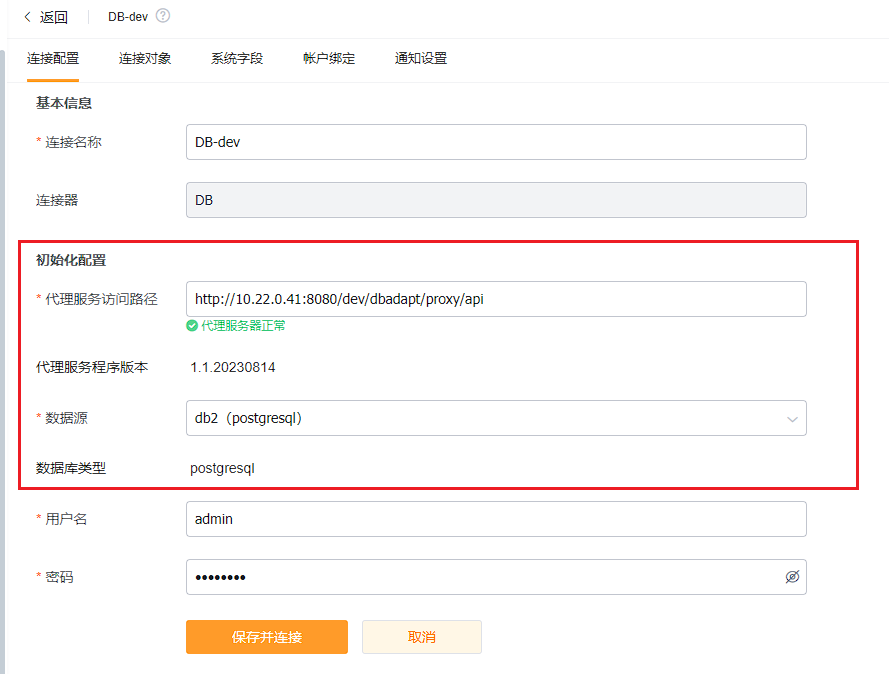 </img></div><div class="editor_js--qiniu_image__caption"></div></div><h3 class="editor_js--header">(2) Query SQL</h3><div class="editor_js--paragraph editor_js--paragraph__align-left">The new proxy supports an offset-free querying mode. Concept and research reference: https://lexiangla.com/teams/k100023/docs/b083d8863b1911ee9801ea708f173910?company_from=050524eee61811e783175254005b9a60</div><div class="editor_js--qiniu_image"><div class="editor_js--qiniu_image__picture">
</img></div><div class="editor_js--qiniu_image__caption"></div></div><h3 class="editor_js--header">(2) Query SQL</h3><div class="editor_js--paragraph editor_js--paragraph__align-left">The new proxy supports an offset-free querying mode. Concept and research reference: https://lexiangla.com/teams/k100023/docs/b083d8863b1911ee9801ea708f173910?company_from=050524eee61811e783175254005b9a60</div><div class="editor_js--qiniu_image"><div class="editor_js--qiniu_image__picture">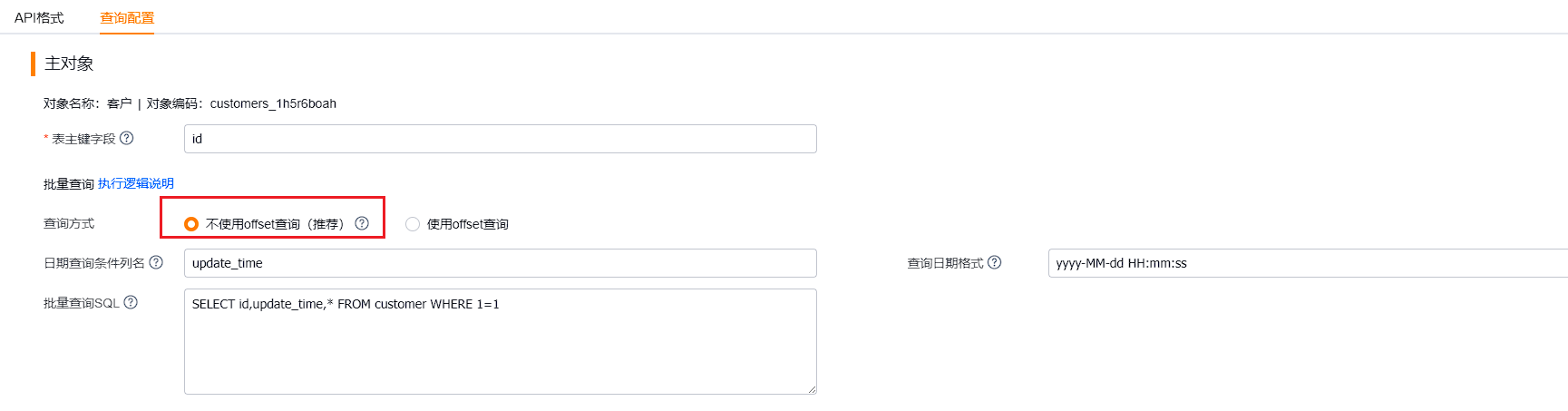 </img></div><div class="editor_js--qiniu_image__caption"></div></div><div class="editor_js--paragraph editor_js--paragraph__align-left">Configuration requirements and notes:</div><ul class="editor_js--list"><li>Use a unique date column for queries.</li><li>The query SQL must select the primary key field and the date field.</li><li>Ensure an appropriate index exists; otherwise queries on large tables will be slow. Test that the SQL uses the index.</li></ul><div class="editor_js--paragraph editor_js--paragraph__align-left">Advantages:</div><ul class="editor_js--list"><li>As long as a newer record never gets updated to an older timestamp, this method prevents missing data.</li><li>With proper indexing you avoid deep pagination and achieve high query performance (index tuning may not be straightforward).</li></ul><div class="editor_js--paragraph editor_js--paragraph__align-left">Example SQL and execution logic:</div><div class="editor_js--paragraph editor_js--paragraph__align-left">Example configuration:</div><div class="editor_js--qiniu_image"><div class="editor_js--qiniu_image__picture">
</img></div><div class="editor_js--qiniu_image__caption"></div></div><div class="editor_js--paragraph editor_js--paragraph__align-left">Configuration requirements and notes:</div><ul class="editor_js--list"><li>Use a unique date column for queries.</li><li>The query SQL must select the primary key field and the date field.</li><li>Ensure an appropriate index exists; otherwise queries on large tables will be slow. Test that the SQL uses the index.</li></ul><div class="editor_js--paragraph editor_js--paragraph__align-left">Advantages:</div><ul class="editor_js--list"><li>As long as a newer record never gets updated to an older timestamp, this method prevents missing data.</li><li>With proper indexing you avoid deep pagination and achieve high query performance (index tuning may not be straightforward).</li></ul><div class="editor_js--paragraph editor_js--paragraph__align-left">Example SQL and execution logic:</div><div class="editor_js--paragraph editor_js--paragraph__align-left">Example configuration:</div><div class="editor_js--qiniu_image"><div class="editor_js--qiniu_image__picture">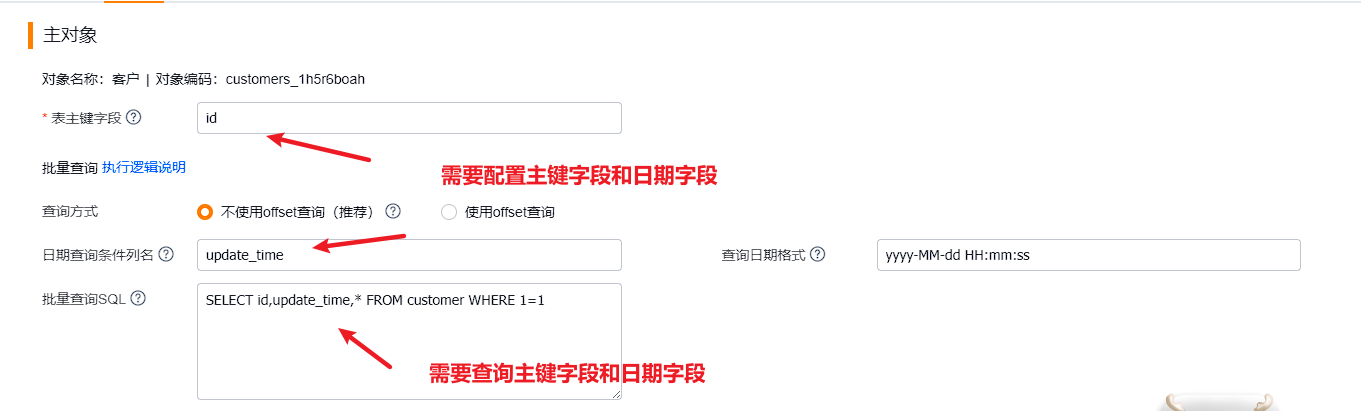 </img></div><div class="editor_js--qiniu_image__caption"></div></div><div class="editor_js--paragraph editor_js--paragraph__align-left">Actual query examples (PostgreSQL):</div>
</img></div><div class="editor_js--qiniu_image__caption"></div></div><div class="editor_js--paragraph editor_js--paragraph__align-left">Actual query examples (PostgreSQL):</div>
</img></div><div class="editor_js--qiniu_image__caption"></div></div><h3 class="editor_js--header">(1) Primary Object</h3><div class="editor_js--qiniu_image"><div class="editor_js--qiniu_image__picture"></img></div><div class="editor_js--qiniu_image__caption"></div></div><div class="editor_js--paragraph editor_js--paragraph__align-left">Query the primary record where the primary key value equals “123”.</div><div class="editor_js--paragraph editor_js--paragraph__align-left">Configurations used: 1 (table primary key field) and 4 (batch query SQL).</div><div class="editor_js--paragraph editor_js--paragraph__align-left">The system automatically generates the criteria: [primaryKeyField=’123’].</div><div class="editor_js--paragraph editor_js--paragraph__align-left">If the batch query SQL contains the placeholder, the system replaces it and produces a single-record query such as: [select * from customer where 1=1 and (id=’123’) order by create_time].</div><div class="editor_js--paragraph editor_js--paragraph__align-left">If there is no placeholder, the criteria are appended to the batch SQL (batch SQL + AND + criteria) to form the single-record query.</div><h3 class="editor_js--header">(2) Sub-object</h3><div class="editor_js--qiniu_image"><div class="editor_js--qiniu_image__picture"></img></div><div class="editor_js--qiniu_image__caption"></div></div><div class="editor_js--paragraph editor_js--paragraph__align-left">When Sub-objects exist, the system iterates the retrieved primary records and reads the primary key value (the primary record id, e.g., “123”).</div><div class="editor_js--paragraph editor_js--paragraph__align-left">It then replaces ‘#pid’ in the Sub-object’s batch query SQL with ‘123’, generating a query like: [select * from customer_detail where 1=1 and pid=’123’] to fetch the related detail rows.</div><h2 class="editor_js--header">2. Batch Query</h2><div class="editor_js--qiniu_image"><div class="editor_js--qiniu_image__picture"></img></div><div class="editor_js--qiniu_image__caption"></div></div><h3 class="editor_js--header">(1) Primary Object</h3><div class="editor_js--qiniu_image"><div class="editor_js--qiniu_image__picture"></img></div><div class="editor_js--qiniu_image__caption"></div></div><div class="editor_js--paragraph editor_js--paragraph__align-left">Start timestamp: 1657092910000, End timestamp: 1657093270000.</div><div class="editor_js--paragraph editor_js--paragraph__align-left">Configurations used: 2 (date query columns), 3 (query date format), and 4 (batch query SQL).</div><div class="editor_js--paragraph editor_js--paragraph__align-left">The system converts the timestamps using the date format from 3, resulting in: Start: 2022-07-06 15:35:10, End: 2022-07-06 15:41:10.</div><div class="editor_js--paragraph editor_js--paragraph__align-left">Using 2 (date query columns): If the setting contains [;], split by [;] into multiple time fields; otherwise split by [,]. The system composes the time criteria by combining each field with the start and end times, resulting in a condition like: [update_time>’2022-07-06 15:35:10’ and update_time<=’2022-07-06 15:41:10’ or create_time>’2022-07-06 15:35:10’ and create_time<=’2022-07-06 15:41:10’].</div><div class="editor_js--paragraph editor_js--paragraph__align-left">Apply the condition to the Primary Object’s batch SQL. If the batch SQL contains the placeholder, replace it; otherwise append the condition to the SQL (batch SQL + AND + condition). Example result: [select * from customer where 1=1 and (update_time>‘2022-07-06 15:35:10’ and update_time<=’2022-07-06 15:41:10’ or create_time>‘2022-07-06 15:35:10’ and create_time<=’2022-07-06 15:41:10’) order by create_time].</div><h3 class="editor_js--header">(2) Sub-object — see Single-record Query logic</h3><div class="editor_js--paragraph editor_js--paragraph__align-left">For Sub-objects, the system iterates the Primary Object results, extracts each primary key value (e.g., ‘123’), replaces ‘#pid’ in the Sub-object’s batch SQL with that ID, and runs queries like: [select * from customer_detail where 1=1 and pid=’123’].</div><h2 class="editor_js--header">3. Create Records</h2><div class="editor_js--qiniu_image"><div class="editor_js--qiniu_image__picture"></img></div><div class="editor_js--qiniu_image__caption"></div></div><h3 class="editor_js--header">(1) Primary Object — Insert</h3><div class="editor_js--qiniu_image"><div class="editor_js--qiniu_image__picture"></img></div><div class="editor_js--qiniu_image__caption"></div></div><div class="editor_js--paragraph editor_js--paragraph__align-left">Example payload: {“masterFieldVal”:{“customer_code”:”code1”},”detailFieldVals”:{“d1obj”:[{“customer_detail_code”:”detailCode1”}]}}</div><div class="editor_js--paragraph editor_js--paragraph__align-left">Configurations used: Primary/Sub-object 5 (SQL to query primary key) and 6 (insert SQL template).</div><div class="editor_js--paragraph editor_js--paragraph__align-left">Apply 6 (insert SQL template) for the primary object: replace ‘#customer_code’ with the primary field value ‘code1’. If ‘#customer_name’ has a null value in the payload, replace it with null. Example resulting SQL: [INSERT INTO customer(customer_code,customer_name) VALUES ( ‘code1’, null)].</div><h3 class="editor_js--header">(2) Primary Object — Query Primary Key</h3><div class="editor_js--qiniu_image"><div class="editor_js--qiniu_image__picture"></img></div><div class="editor_js--qiniu_image__caption"></div></div><div class="editor_js--paragraph editor_js--paragraph__align-left">Apply 5 (SQL to query primary key): replace ‘#customer_code’ with ‘code1’ and run: [select id from customer where 1=1 and customer_code=’code1’] to retrieve the inserted primary key.</div><h3 class="editor_js--header">(3) Sub-object — Insert</h3><div class="editor_js--qiniu_image"><div class="editor_js--qiniu_image__picture"></img></div><div class="editor_js--qiniu_image__caption"></div></div><div class="editor_js--paragraph editor_js--paragraph__align-left">Apply 6 (insert SQL template) for the Sub-object: replace ‘#customer_detail_code’ with ‘detailCode1’. If ‘#customer_detail_name’ is null, replace it with null. The preliminary insert SQL becomes: [INSERT INTO customer_detail (pid,customer_detail_code,customer_detail_name) VALUES ( ‘#pid’, ‘detailCode1’, null)].</div><h3 class="editor_js--header">(4) Sub-object — Query Primary Key</h3><div class="editor_js--qiniu_image"><div class="editor_js--qiniu_image__picture"></img></div><div class="editor_js--qiniu_image__caption"></div></div><div class="editor_js--paragraph editor_js--paragraph__align-left">Apply 5 (SQL to query primary key) for the Sub-object: replace ‘#customer_detail_code’ with ‘detailCode1’ and ‘#pid’ remains as ‘#pid’ until the primary key is available. Preliminary SQL: [select detailId from customer_detail where 1=1 and pid=’#pid’ and customer_detail_code=’detailCode1’].</div><h3 class="editor_js--header">(5) Execution Order for Primary/Sub-object SQL (Non-transactional)</h3><div class="editor_js--paragraph editor_js--paragraph__align-left">1. Execute the primary object INSERT SQL.</div><div class="editor_js--paragraph editor_js--paragraph__align-left">2. On success, run the primary object’s SQL to query the newly inserted primary key (for example, ‘1234’).</div><div class="editor_js--paragraph editor_js--paragraph__align-left">3. Replace ‘#pid’ in the Sub-object’s INSERT and primary-key-query SQL with ‘1234’, producing final Sub-object SQL such as: [INSERT INTO customer_detail (pid,customer_detail_code,customer_detail_name) VALUES ( ‘1234’, ‘detailCode1’, null)] and [select detailId from customer_detail where 1=1 and pid=’1234’ and customer_detail_code=’detailCode1’].</div><div class="editor_js--paragraph editor_js--paragraph__align-left">4. Execute the Sub-object INSERT SQL, then the Sub-object primary-key query SQL.</div><h2 class="editor_js--header">4. Update Records</h2><div class="editor_js--qiniu_image"><div class="editor_js--qiniu_image__picture"></img></div><div class="editor_js--qiniu_image__caption"></div></div><h3 class="editor_js--header">(1) Primary Object — Update</h3><div class="editor_js--qiniu_image"><div class="editor_js--qiniu_image__picture"></img></div><div class="editor_js--qiniu_image__caption"></div></div><div class="editor_js--paragraph editor_js--paragraph__align-left">Example payload: {“masterFieldVal”:{“customer_code”:”code1”,”id”:”1234”},”detailFieldVals”:{“d1obj”:[{“customer_detail_code”:”detailCode1”,”detailId”:”12345”}]}}</div><div class="editor_js--paragraph editor_js--paragraph__align-left">Configurations used: Primary/Sub-object 7 (update SQL). If the Sub-object contains new detail rows, the Sub-object’s 5 (SQL to query primary key) and 6 (insert SQL template) are also used.</div><div class="editor_js--paragraph editor_js--paragraph__align-left">Apply 7 (update SQL) for the primary object: replace ‘#customer_code’ with ‘code1’ and ‘#id’ with ‘1234’. Resulting SQL: [UPDATE customer SET customer_code = ‘code1’ WHERE id = ‘1234’].</div><h3 class="editor_js--header">(2) Sub-object — Update</h3><div class="editor_js--qiniu_image"><div class="editor_js--qiniu_image__picture"></img></div><div class="editor_js--qiniu_image__caption"></div></div><div class="editor_js--paragraph editor_js--paragraph__align-left">Apply 7 (update SQL) for the Sub-object: replace ‘#customer_detail_code’ with ‘detailCode1’ and ‘#detailId’ with ‘12345’. Example resulting SQL: [UPDATE customer_detail SET customer_detail_code = ‘detailCode1’ WHERE detailId = ‘12345’].</div><div class="editor_js--paragraph editor_js--paragraph__align-left">If the Sub-object contains new records, follow the Sub-object insert steps described above. Deletion (logical or physical) of Sub-object rows is not supported at this time.</div><h1 class="editor_js--header">5. New Version Features</h1><div class="editor_js--paragraph editor_js--paragraph__align-left">Newly provisioned connectors now require proxy service version 1.1 or above.</div><h2 class="editor_js--header">1. Proxy Service v1.1</h2><h3 class="editor_js--header">(1) New Features</h3><ul class="editor_js--list"><li>Support configuration of multiple data sources. Supported database engines: MySQL, PostgreSQL, Oracle, SQLServer.</li><li>Support external JDBC driver jars to access databases beyond built-in drivers. DM8 (Dameng) has been tested.</li><li>New, simplified configuration file format.</li><li>New APIs to expose service information for the Integration Platform.</li><li>Support executing multiple SQL statements per query to enable offset-free polling scenarios that require two SQLs per cycle.</li><li>Improved error handling and broader exception capture.</li><li>Upgraded dependent libraries (including Spring Boot, fastjson, etc.) to mitigate vulnerabilities.</li><li>Enabled Druid statistics.</li><li>Compatibility across Integration Platform environments (the Integration Platform may host multiple environment versions; older platform environments can still access newer proxy service versions).</li></ul><h3 class="editor_js--header">(2) Deployment Notes</h3><div class="editor_js--paragraph editor_js--paragraph__align-left">Attached are the proxy program JARs for versions 1.0 and 1.1.</div><div class="editor_js--paragraph editor_js--paragraph__align-left">Configuration files:</div><div class="editor_js--paragraph editor_js--paragraph__align-left">There are two configuration approaches. The first uses Spring Boot configuration. By default the JAR runs with Spring’s ‘prod’ profile, so you may create an application-prod.yml in the same directory as the JAR to add settings. Example:</div># application-prod.yml
setting:
# Directory for configuration files. You can use a relative path. If omitted, the default is the "setting" folder under the working directory.
dir: D:\project\DBMidProxyServer\setting
server:
servlet:
context-path: /dev
<div class="editor_js--paragraph editor_js--paragraph__align-left">The second approach uses Hutool configuration files. The system supports dynamic loading for user.setting but not yet for db.setting. The directory specified by setting.dir must contain db.setting and user.setting.</div># user.setting
# Security configuration
username=admin
password=1234qwer
# db.setting — database configurations
# For Druid settings reference: https://github.com/alibaba/druid/wiki/DruidDataSource%E9%85%8D%E7%BD%AE%E5%B1%9E%E6%80%A7%E5%88%97%E8%A1%A8
# Each group name becomes the datasource name
[db1]
url=jdbc:postgresql://localhost:5432/db1?ssl=false
username=postgres
password=1234qwer
queryTimeout=30
initialSize=5
maxActive=20
testWhileIdle=true
[db2]
url=jdbc:postgresql://localhost:5432/db2?ssl=false
username=postgres
password=1234qwer
queryTimeout=30
initialSize=5
maxActive=20
testWhileIdle=true
[db3]
# MySQL
url=jdbc:mysql://localhost:3306/db3?useSSL=false&characterEncoding=UTF-8&connectionTimeZone=Asia/Shanghai
username=root
password=1234qwer
queryTimeout=30
initialSize=5
maxActive=20
testWhileIdle=true
[db4]
# SQL Server
url=jdbc:sqlserver://;serverName=localhost;databaseName=db4;encrypt=true;trustServerCertificate=true
username=sa
password=8kn0ye66JxO5
queryTimeout=30
initialSize=5
maxActive=20
testWhileIdle=true
[db5]
# Oracle
url=jdbc:oracle:thin:@127.0.0.1:1521:XE
username=dbproxy
password=1234qwer
queryTimeout=30
initialSize=5
maxActive=20
testWhileIdle=true
[dm8]
# Dameng (additional driver required)
url=jdbc:dm://localhost:5236?LobMode=1
username=SYSDBA
password=SYSDBA001
queryTimeout=30
initialSize=5
maxActive=20
testWhileIdle=true
# For databases without built-in drivers, specify the JDBC driver JAR path.
driverJarPath=D:\driver\db-driver\DmJdbcDriver18.jar
<div class="editor_js--paragraph editor_js--paragraph__align-left">Run command:</div>java -jar DBMidProxyServer.jar
<h2 class="editor_js--header">2. Integration Platform Configuration</h2><div class="editor_js--paragraph editor_js--paragraph__align-left">Note: The following features require the new proxy service. Existing configurations continue to work. To use the new features, deploy proxy service v1.1 or later.</div><h3 class="editor_js--header">(1) Connection Info</h3><div class="editor_js--paragraph editor_js--paragraph__align-left">After deploying the new proxy service, the Integration Platform can query the proxy via APIs to obtain service version, datasource information, database types, and other metadata.</div><div class="editor_js--paragraph editor_js--paragraph__align-left"></div><div class="editor_js--qiniu_image"><div class="editor_js--qiniu_image__picture"></img></div><div class="editor_js--qiniu_image__caption"></div></div><h3 class="editor_js--header">(2) Query SQL</h3><div class="editor_js--paragraph editor_js--paragraph__align-left">The new proxy supports an offset-free querying mode. Concept and research reference: https://lexiangla.com/teams/k100023/docs/b083d8863b1911ee9801ea708f173910?company_from=050524eee61811e783175254005b9a60</div><div class="editor_js--qiniu_image"><div class="editor_js--qiniu_image__picture"></img></div><div class="editor_js--qiniu_image__caption"></div></div><div class="editor_js--paragraph editor_js--paragraph__align-left">Configuration requirements and notes:</div><ul class="editor_js--list"><li>Use a unique date column for queries.</li><li>The query SQL must select the primary key field and the date field.</li><li>Ensure an appropriate index exists; otherwise queries on large tables will be slow. Test that the SQL uses the index.</li></ul><div class="editor_js--paragraph editor_js--paragraph__align-left">Advantages:</div><ul class="editor_js--list"><li>As long as a newer record never gets updated to an older timestamp, this method prevents missing data.</li><li>With proper indexing you avoid deep pagination and achieve high query performance (index tuning may not be straightforward).</li></ul><div class="editor_js--paragraph editor_js--paragraph__align-left">Example SQL and execution logic:</div><div class="editor_js--paragraph editor_js--paragraph__align-left">Example configuration:</div><div class="editor_js--qiniu_image"><div class="editor_js--qiniu_image__picture"></img></div><div class="editor_js--qiniu_image__caption"></div></div><div class="editor_js--paragraph editor_js--paragraph__align-left">Actual query examples (PostgreSQL):</div>-- Query data between T1 and T2– First query
select * from customer where update_time>T1 and update_time<=T2 ordey by update_time,id limit 100
– Subsequent queries:
– {lastMaxUpdateTime} and {lastMaxId} are replaced every cycle with the last returned row’s update_time and id
select * from customer where update_time={lastMaxUpdateTime} and id > {lastMaxId} ordey by update_time,id limit 100
select * from customer where update_time> {lastMaxUpdateTime} and update_time<=T2 ordey by update_time,id limit 100
</code><div class="editor_js--paragraph editor_js--paragraph__align-left">Therefore, create a composite index on (update_time, id) in the database (DBAs must perform this):</div>
-- Database index
CREATE INDEX idx_id_update_time ON customer (update_time,id);
<div class="editor_js--paragraph editor_js--paragraph__align-left">Supported dialects: PostgreSQL, MySQL, Oracle, SQLServer</div><div class="editor_js--paragraph editor_js--paragraph__align-left"></div><div class="editor_js--paragraph editor_js--paragraph__align-left"></div><div class="editor_js--paragraph editor_js--paragraph__align-left"></div><div class="editor_js--attaches"><div class="editor_js--attaches__file-icon" data-extension="zip" style="color: #4f566f;"></div><div class="editor_js--attaches__file-info"><div class="editor_js--attaches__title">DBMidProxyServer-1.1.zip</div><div class="editor_js--attaches__size">80.3 MB</div></div></div><div class="editor_js--paragraph editor_js--paragraph__align-left"></div><div class="editor_js--attaches"><div class="editor_js--attaches__file-icon" data-extension="zip" style="color: #4f566f;"></div><div class="editor_js--attaches__file-info"><div class="editor_js--attaches__title">DBMidProxyServer-1.0.zip</div><div class="editor_js--attaches__size">68.8 MB</div></div></div><div class="editor_js--attaches"><div class="editor_js--attaches__file-icon" data-extension="zip" style="color: #4f566f;"></div><div class="editor_js--attaches__file-info"><div class="editor_js--attaches__title">DBMidProxyServer-1.3.zip</div><div class="editor_js--attaches__size">84.7 MB</div></div></div><div class="editor_js--paragraph editor_js--paragraph__align-left"></div>